
This is an extremely compressed overview on the current state of hallucinations research, intended to provide research direction and starting considerations for building hallucination resilience into LLM-powered applications. While industry leaders had overly optimistic takes two years ago, hallucinations remain a key bottleneck, may have become even more prevalent with reasoning models, and stay an active research area.
🎯 Key Takeaways:
- Newer models do NOT hallucinate less: Reasoners and higher complexity tasks over longer contexts can cause MORE hallucinations.
- RAG does not "fix" hallucinations: Hallucinations are not just a gap in factual knowledge; adding relevant context isn't a silver bullet.
- Snowballing effect: Likelihood increases once a hallucination is in context, an effect not measured in current single-turn benchmarks.
- CoT Faithfulness: Chains of Thought are NOT always faithful to their internal outputs; they can be hindsight-justified explanations.
Towards a Working Understanding
Hallucinations are:
- Unreasonable inferences from either training data or in-context data for a given prompt.
- Not strictly about factual correctness (they can manifest even with source-dependent knowledge).
- Circuit-level overrides: Instances where model internals indicate a refusal, but are overridden by other features (e.g., "I have seen this before, trust me").
Hallucination Example: Short-Circuiting Refusals
Anthropic's research into the "default refusal circuit" show how a model might hallucinate when pushed. By probing features like the Can't Answer feature, researchers can inhibit or amplify responses.
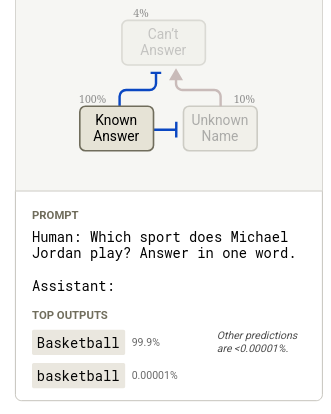 Michael Jordan prompt/output vs attribution features graph analysis.
Michael Jordan prompt/output vs attribution features graph analysis.
Initially, the model refuses or answers appropriately, but these circuits can be inhibited with interventions. Amplifying the Can't Answer circuit by 20x magnitude might cross the Known Answer threshold for Basketball, leading to a hallucination where the model responds with the refusal.
Example 2: Hindsight-Justified Reasoning
In mathematical tasks, if a user provides a wrong answer for the model to verify, the model often pretends to hindsight-justify that answer, preferring a "confident" response over factual correctness or admitting uncertainty. This may be an after-effect of human preference training (RLHF).
Implications for Setting Up Hallucination Evals
- Drop naive QA benchmarks: Since training data remains secret, checking for source-independent world knowledge is better replaced with in-context detection.
- Mech-interp is limited: Closed weights models cannot be introspected. Prompt search (per-model and per-domain) is the only viable tool to reduce hallucinations on forward passes.
- Multi-turn is essential: Single-turn benchmarks fail to capture effects like "snowballing."
Comprehensive Approach
- Multi-turn workflows: Using the same model to critique its own outputs (majority voting) beats single-turn.
- Verification via Judge Agents: Use agents with tools to run experiments on outputs (e.g., Root Judge).
- Domain expert review: Use expert feedback to build a baseline for cold start data and case-specific evaluations.
- Scorable Platform: Observe differences between providers and prompts with head-to-head comparisons on the Scorable Platform.
References and Further Reading
- Transformer Circuits - Insights on Default Refusal Circuits and CoT Faithfulness.
- Circuit Tracer Tool - Key Mechanistic Interpretability tool.
- Root Judge - Our open weights LLM Judge for exploring these boundaries.