Scorable creates and runs AI Auditors that keep your AI truthful, compliant, and on-target in production.
Pain: Your AI is one bad response away from a compliance incident.
Ensure AI responses stay within your business rules, legal constraints, safety requirements, and brand guidelines.
Pain: You don't know if your AI is actually helpful until a customer complains.
Measure whether AI responses are accurate, complete, clear, and genuinely useful — before they reach your users.
Pain: Every model update is a gamble — you never know what silently broke.
Catch quality regressions and behavioral changes automatically when you swap models, update prompts, or release new versions.
Pain: Your AI drifts in production and nobody notices until it's too late.
Continuously evaluate real user interactions in production to catch quality degradation, hallucinations, and policy drift as they happen.
Pain: Your AI tries to handle situations it should never touch.
Identify when AI responses should be escalated to a human agent — based on frustration, complexity, sensitivity, or safety risk.
Pain: Agents act first and ask for forgiveness later.
Evaluate what an agent is about to do, not just what it says. Prevent wrong actions before they cause real impact.
Pain: You're making decisions about AI quality without any baseline data.
Analyze past AI interactions in bulk to establish a baseline and find recurring problems before making changes.
Create AI judge for Policy and compliance guardrails ↓
Non-deterministic systems can fail semantically, not just technically
AI auditors evaluate every call against the behaviors you care about
Scorable scores every AI response with a plain-language justification. No digging through logs. No waiting for a user complaint. Just a clear picture of what your AI is doing, right now.
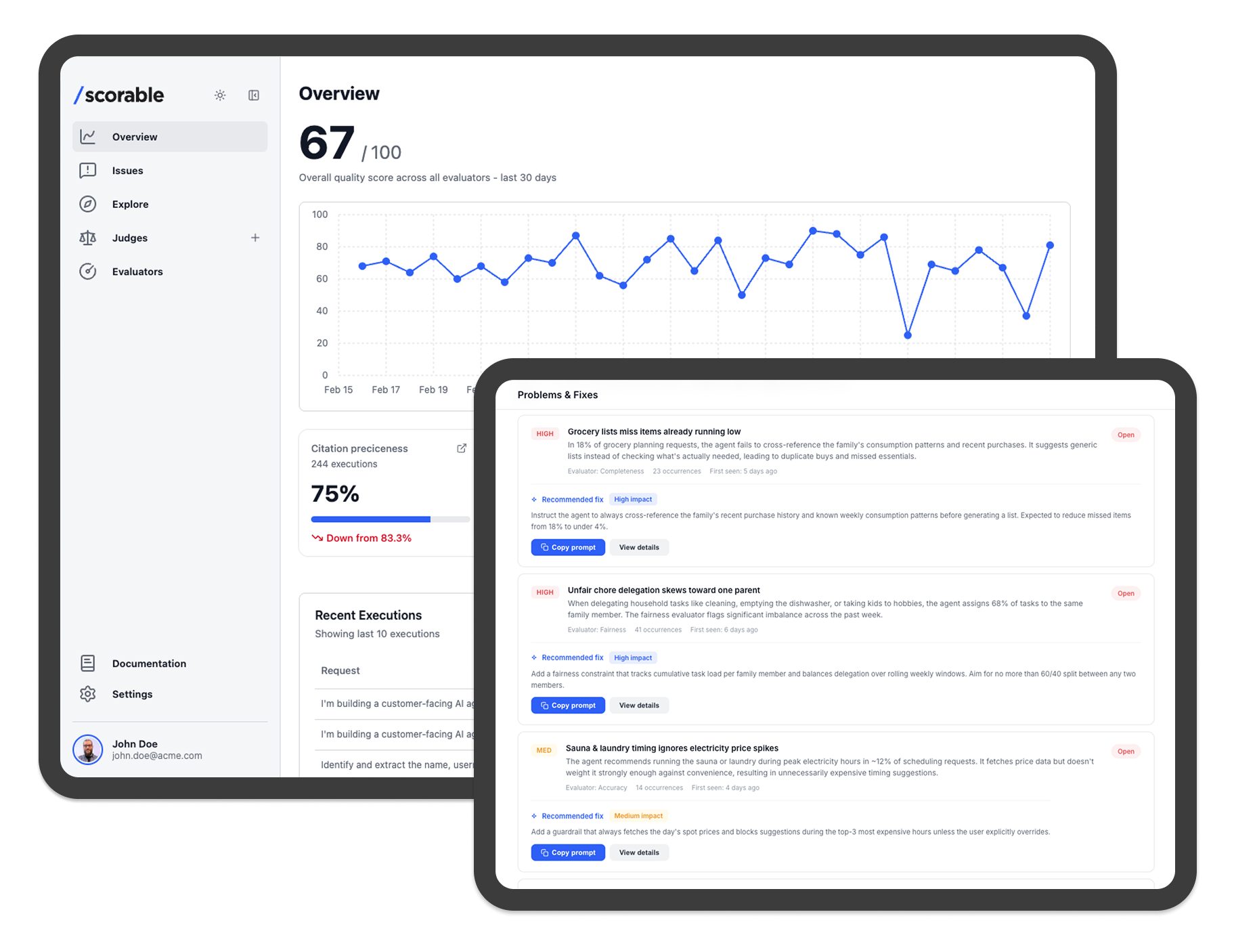
Know exactly why a response failed
Score + plain-language justification for every output. Debugging in minutes, not hours.
Catch problems before users do
Proxy mode flags or rectifies non-compliant responses before they reach anyone.
Go systematic today
No months of data labeling. No framework to build from scratch.
Calibrate trust, not just measure
Attach ground-truth examples and measure how closely evaluators track your judgment.
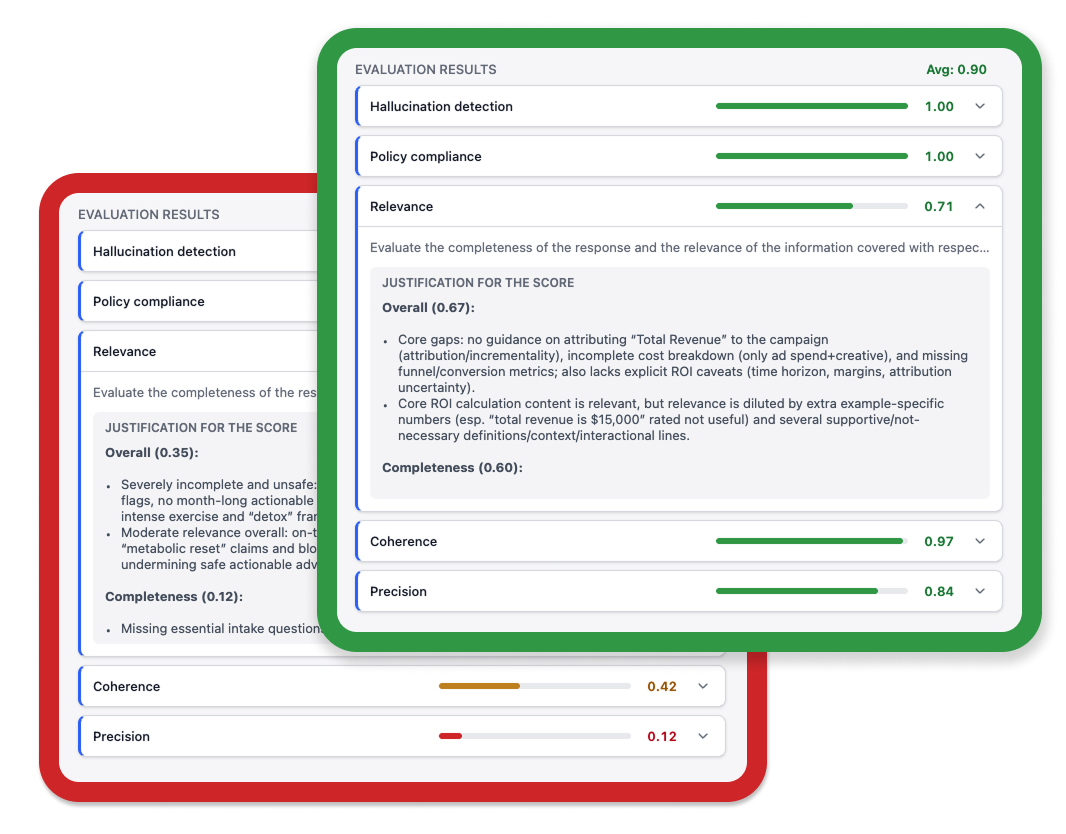
When an evaluator flags a problem, you get the score, the reason, and the exact response that failed. Fix the prompt, update the evaluator, and verify the change. Systematic improvement, not guesswork.
100 free evals/day · no credit card required